
What is structured, semi structured and unstructured data, difference between structured data and unstructured data, Image processing with big data


The Previous blog is about what is big data and the characteristics of data in the concept of 5 V’s. In this article, we will see what are the classification of big data? which is structured, semi-structured, and unstructured data. So we get to know how the data can be stored, process, and analyze. Big data is nothing but say the huge volume of data that cannot be stored and process using a traditional system within given time officiants.
What is Structured Data?
Structured data is any data that can be stored, accessed, and processed in the form of fixed-format which is easy to execute. Structured data have some format associated with them. It is data with a high degree of organization. Example: Data in databases, data in excel format.
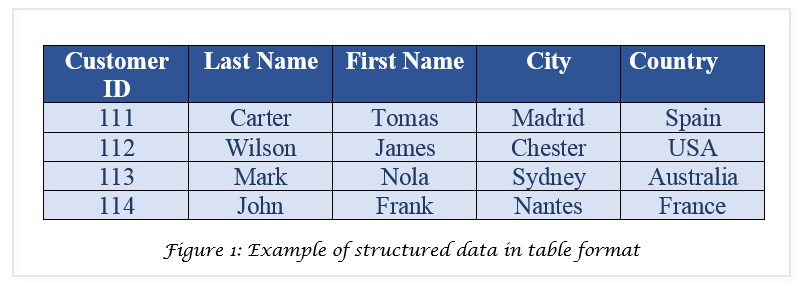
This table created using a spreadsheet is an example of structured data. The table structure makes this type of data ready for analysis. For example, we could filter the table for a customer living in a specific city. Another example of structured data is the comma-separated value or CSV files.

If you look at this image it follows a structure that can be converted into a table. These values are separated by a comma so they
can be related to a table. For example, every second value in a row
indicates a timestamp. Thus structured data has a well-defined
structure. It follows a consistent order and is defined in such a way that
it can be easily accessed and used by a person or a computer.
What is Semi-Structured Data?
Semi-structured data does not have some proper form associated with it.
The data over the emails, the data in Word format or PDF so they are they
fall under semi-structured data. An example of this data is a hypertext
markup language file. It is a file with text that has some structure like
head, title, paragraph, etc. These structures are defined by tags texts in
it are organized with those tags.

For example title tag instructs the browser what to show on the title bar
h1 tag stands for heading 1 that commands the browser to display the text
with that specific format these tags organize the file and what will be
displayed on the browser. But on a different web page, the number and type
of tags used might be completely different. Therefore this data contains
structured in form but it is not as defined similarly to what appears on a
table.
What is Unstructured Data?
Unstructured data is defined as any data with no pre-defined
organizational form or specific format associated with it. This can be
data of any file format which is not put into a spreadsheet or some
semi-structured data format.

Examples of unstructured data are any file type returned by google
searches like jpeg, png, mp3, mp4, pdf, or any other file type the common
characteristic of these files is there is no structure on its content.
Organizations have a wealth of data and the vast majority of all data
created today is unstructured. For humans, unstructured data is easy to consume but for a computer, it is difficult to analyze and
interpret because it has no degree of organization. With the advent of
artificial intelligence, machine learning specifically there is now a lot
of progress in processing and essentially teaching a machine how to read
and understand unstructured data.
For example, the fields of natural language processing that allow humans
to interact with computers. Computer vision that allows computers to
recognize objects from images and videos is witnessing significant
breakthroughs at the moment.
·
Medical records, Social media, Business documents
·
Images, video, and audio media content
·
Communications- messaging and digital meetings
·
Survey responses
·
Publications and listings
·
Web pages are some of the examples of unstructured data.
The unstructured data is divided into:
Ø
Captured data:
Data based on user’s behavior
Ø
User-generated data:
User-created data on the internet
According to IBM 90% of data capture, today is structured that's huge
there is this 90% of unstructured data that do not handleable using
traditional systems. Because they can only handle structured data. These
unstructured data are generated from sensors used to gather climate
information, social media, web pictures, and videos, industrial sensors, buy transaction records, mobile phone signals.
Note:
Structured data can be handled through a traditional system.
Semi-structured data and unstructured data can only be handled through the Hadoop system.
Difference between Structured Data and Unstructured Data
Structured data can be displayed in rows, columns, and relational
databases. Unstructured data cannot be row-column or relational
databases.
Structured data are numbers, dates, and strings. Unstructured data are
Images, audio, video, word processing files, e-mails, spreadsheets.
Structured data estimated 20% of enterprise data. Unstructured data
estimated 80% of enterprise data.
Structured data are easy to manage and protect with legacy solutions.
Unstructured data are more difficult to manage and protect with legacy
solutions.
Image Processing with Big Data
Every day hospitals produce tens of thousands of diagnostic and clinical
images resulting from x-rays, digital tomographies, magnetic resonances,
PET, and angiographies. Each image is tagged with labels that provide
information on patients’ records, clinical protocols, the patient’s body
parts concerned, and the medical instrumentation used.
But, metadata can be incomplete or wrong. For instance, an abdominal examination can include images of the chest or even of the entire body. Selecting and classifying images is a quite critical phase. When the information extracted from metadata is scarce, the process may take too long or provide inaccurate results. Processing images through Machine Learning techniques provides a new approach to image classification.
For each image, the system locates the part of the body concerned, on
which it performs various complex measurements. This way new information
is collected and added to existing metadata for future use. Once the
information is stored, an algorithm uses the results of image processing and classifies the image according to the part of the body concerned. The
time needed to select and classify images has been reduced by 90% with a
margin of error of 10%. Now analysts can focus right from the beginning
only on the improvement of clinical search parameters.








COMMENTS